
项目名称基本格式:基于(方法)的(场景)的(任务)
一、论文选择
研究全链路:异常检测->检测结果处理->根因定位(很热门的技术)->修改建议
本篇论文针对的是检测结果处理部分
本文围绕软件崩溃报告的近重复检测展开研究,提出了一种名为DeepLSH的深度局部敏感哈希学习方法,旨在解决大规模崩溃报告场景下,快速、高效的近重复匹配问题
近重复:内容一致,但结构存在微小差异
精确重复:完全一致
LSH(Locality-Sensitive Hashing,局部敏感哈希)是一类“快速查找相似数据”设计的哈希技术,其核心思想是:相似的数据经过哈希函数处理后,很大概率被映射到同一个“哈希桶”(bucket),而不相似的数据,映射到同一个桶的概率极低。
- 局部:聚焦数据在特征空间中的邻近区域,仅关注局部范围内的样本距离关系
- 敏感:对样本间的局部邻近性保持敏感,近邻样本哈希结果趋同,远隔样本则相异
- 哈希:通过哈希函数将高维数据映射至低维空间,实现高效的近邻检索与数据分桶
它和“普通哈希”(MD5、SHA等)完全相反:
普通哈希是为了“避免碰撞”,让不同数据尽量映射到不同桶,常用于加密、去重等
LSH是为了“主动制造相似数据的碰撞”,让相似数据聚集在同一个桶,从而快速缩小相似性搜索的范围。
二、论文的结构
- 摘要 Abstract
- 介绍 Introduction
- 相关工作 Related Work
- 问题定义/背景 Problem Definition / Background
- 模型 Model
- 实验 Experiments
- 总结/不足之处 Conclusion / Limitations
三、摘要
自动崩溃分组是软件开发中故障报告分流的关键环节,核心是通过聚类分组相似报告,但实时流式故障收集场景下,需要快速定位新报告的近重复项,而传统方法效率不足。
局部敏感哈希(LSH)因亚线性性能和相似性搜索准确性的理论保证,适合大规模数据集,但现有LSH函数难以适配崩溃分组领域的复杂相似性度量,故未被广泛应用。
为此,论文提出DeepLSH,一种基于孪生深度神经网络(DNN)的架构,搭配原创损失函数,可完美逼近局部敏感特性,即便对已有精确LSH方案的Jaccard和Cosine度量也适用。通过在原创数据集上的实验验证了该方法的有效性。
四、介绍
1.背景与需求
软件发布后会产生大量崩溃报告(含Java堆栈跟踪和上下文信息),报告优先级各异(罕见意外停机、高频GUI问题,静默后台故障等),需要快速分组近重复报告以加速故障排查,企业每日接受上万条报告、传统方法难以满足准实时处理需求(如1000条报告与10万条历史报告匹配需10小时)
2.现有方法缺陷
传统崩溃去重依赖字符串匹配、信息检索等定制相似性度量,嵌入聚类算法中存在三大问题:相似性计算量大、聚类结果不稳定(需要频繁重新计算)、参数调优困难
3.LSH的潜力与挑战
LSH能高效解决近似最近邻搜索(ANN),但现有LSH函数仅支持特定相似性度量(如MinHash对应Jaccard、SimHash对应Cosine),无法适配崩溃分组的复杂度量,导致其未被应用于该领域
4.研究目标
①实现准实时处理,快速判断新报告是否存在对应工单(更新统计)或需创建新工单,
②同时支持多种相似性度量。
5.核心贡献
①提出通用框架DeepLSH,学习满足局部敏感特性的二进制哈希函数,高效检索近重复堆栈跟踪
②设计孪生神经网络架构与原创损失函数,结合正则化解决二值化优化问题
③在真实大规模数据集上验证,对比标准LSH和深度哈希基线,证明其有效性与扩展性
五、相关工作
1.传统 LSH 研究
LSH 在理论计算机领域被广泛研究,核心是生成满足局部敏感特性的随机哈希函数族,如 MinHash 适配 Jaccard 相似度、SimHash 适配余弦 / 角距离,但这些方法仅支持特定度量,无法扩展到其他相似性指标。在软件工程领域,LSH 仅被用于代码搜索、克隆检测等场景,未满足崩溃去重 —— 因崩溃分组的现有度量难以适配传统 LSH 函数。
2.学习哈希研究
学习哈希是计算机视觉领域的热点,通过深度学习将数据映射为低维哈希码,同时保留相似性,但这类方法缺乏 LSH 的理论保证,无法系统构建哈希表,也不能通过参数调控 Hamming 召回率的权衡。现有相关基线(如 CNN+LSH)采用 “先学习哈希码、后离散化应用哈希表” 的两阶段方法,未将 LSH 特性嵌入训练过程,导致性能下降。
2.堆栈跟踪相似性度量
现有崩溃去重研究聚焦于设计定制化相似性度量,主要分为三类:①基于信息检索与字符串匹配(如 Lucene 的 TF-IDF 评分、N-gram + 余弦相似度、编辑距离);②基于堆栈跟踪特性(如 Brodie 的帧频率与位置调整、PDM 的帧偏移距离、TraceSim 的帧位置与全局逆频率结合);③混合度量(如 Moroo 结合 TF-IDF 与 PDM)。论文的 DeepLSH 不提出新的相似性度量,而是与现有度量互补,为其提供高效、可扩展的近重复检索能力。
六、 背景与目标
1.核心概念
软件崩溃 / 错误(文中两者同义)指应用无响应、后台任务失败或弹窗报错等场景,每条崩溃报告包含两部分核心信息 ——Java 堆栈跟踪(函数调用链路、代码位置、异常类型)和运行时上下文(软件 / OS / 数据库版本、时间戳、用户操作描述)。
2.堆栈跟踪细节
Java 堆栈跟踪按 “内层调用→外层调用” 排序,顶层帧是崩溃发生的直接位置(例:com.company.CABWrapper.read(CABWrapper.java:191) 为核心故障帧),是判断崩溃根因的关键。
3.数据来源
来自于 B2B 企业资源规划(ERP)系统开发与部署公司的历史崩溃报告数据库,超过 10w 条数据。
4.问题核心
在保证模型性能的稳定性下,提高模型的通用性和高效性
- 通用性:支持任意堆栈跟踪相似性度量(无需手动设计 LSH 函数)
- 高效性:检索时间为亚线性或常数时间,适配大规模数据集
- 理论保证:保留 LSH 的局部敏感特性和概率保证,可调节精度 – 召回率
七、模型
DeepLSH是一款融合“孪生神经网络”与“局部敏感哈希(LSH)核心特性”的端到端哈希学习模型
1.孪生神经网路
两个结构完全一样、权重完全共享的 “双胞胎” 神经网络,专门用来判断:两个输入长得到底像不像。
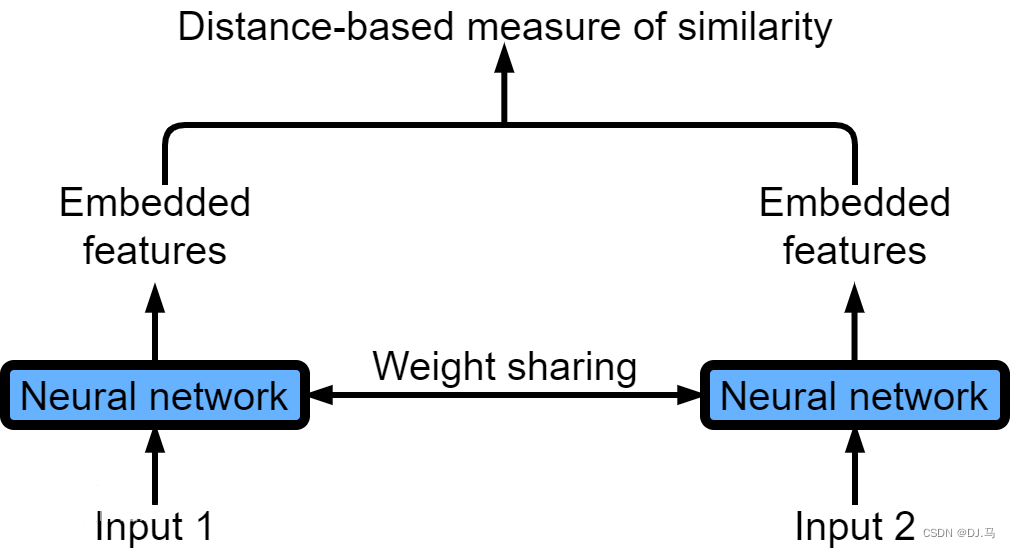
用两个不同的神经网络同时训练,不行
用两个相同的神经网络先后训练,不行
用两个相同的神经网络同时训练,共享权重,可以
2.局部敏感哈希(文章核心创新点)

3.端到端哈希学习模型
从原始输入直接输出最终结果,中间不拆分人工步骤,让模型自己学会所有映射关系。