
论文链接:1706.03762
一、研究背景
在Transformer模型出现以前,很多语言模型是基于RNN(循环神经网络)的,比如LSTM(长短时记忆网络)或GRU(门控循环单元)的,这些模型在处理输入时,是按照顺序逐个处理输入的。这种处理方式存在两个不足:
- 只能串行计算,计算效率低:后一个神经元的计算依赖前一个神经元的输出,无法并行计算。
- 难以捕捉长距离依赖关系:当文本长度过长时,RNN很难捕捉长距离的依赖关系。
为了解决这两个不足,Transformer横空出世,具有如下优势:
- 可以并行计算,计算效率高:抛弃了 RNN 的串行依赖,序列中每个 token 的计算相互独立,可一次性并行完成,再借助 GPU 矩阵运算实现高效并行。
- 能够捕捉长距离依赖关系:自注意力机制可以让模型很容易地捕捉到句子中长距离的依赖关系。
- 可扩展性好:Transformer的结构比较简单,很容易扩展到更大的模型,如BERT,GPT,Qwen等模型。
Transformer统一了 NLP 领域的技术范式,还延伸到计算机视觉、多模态等领域,成为当下大模型时代的基础架构。Transformer 在多个领域展现了强大的能力:
- 自然语言处理(NLP):在机器翻译、语言建模、文本分类等任务上取得了显著成果。例如,BERT、GPT 等模型均基于 Transformer 架构。
- 计算机视觉(CV):Vision Transformer(ViT)等模型将 Transformer 应用于图像分类、目标检测等任务。
- 时间序列分析:Transformer 被用于时间序列数据的去噪和预测。
二、模型架构
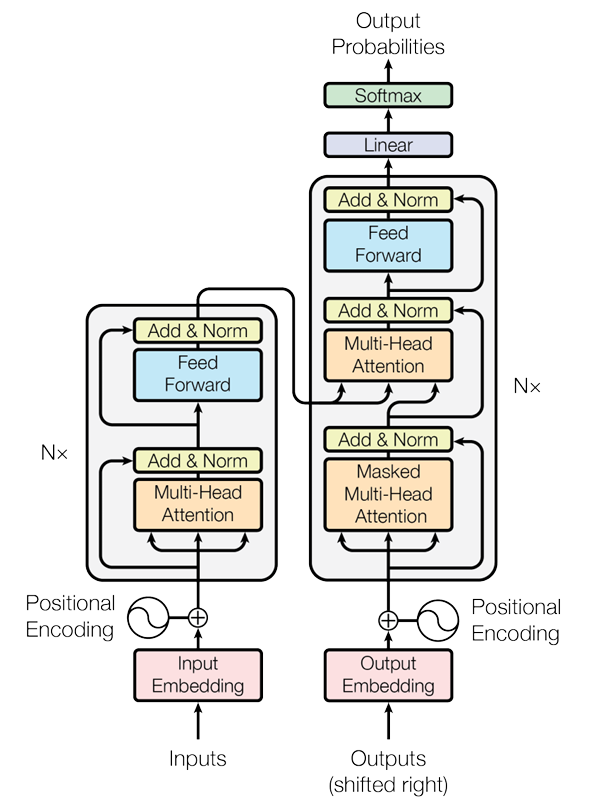
Transfomer的核心架构由编码器(Encoder)和解码器(Decoder)组成。
1.编码器:将输入序列编码为固定长度的向量。
编码器由多个相同的层堆叠而成,每层包含两个主要的子层:
- 多头注意力(Multi-Head Self-Attention):通过将输入序列分割成多个子空间,分别计算注意力权重,从而捕捉不同位置之间的关系。
- 前馈神经网络(Feed-Forward Neural Network):对每个位置的特征进行非线性变换。
- 其他组件:残差链接(Residual Connection)和层归一化(Layer Normalization),以减轻训练过程中的梯度消失和梯度爆炸问题。
2.解码器:根据编码器的输出生成目标序列。
解码器由多个相同的层堆叠而成,每层包含三个主要的子层:
- 掩码多头自注意力(Masked Multi-Head Self-Attention):确保解码器只能关注目标序列中当前和之前的位置,防止数据泄露(用未来预测现在)。
- 编码器-解码器自注意力(Encoder-Decoder Attention):将解码器的状态与编码器的输出结合,捕获输入和输出之间的关系。
- 前馈神经网络(Feed-Forward Neural Network):对每个位置的特征进行非线性变换。
三、训练流程
我们将英文句子”Hello, how are you?”翻译成中文”你好,你好吗?”为例,详细说明 Transformer 在机器翻译中的迭代生成过程。为了简化说明,我们假设模型已经训练完成,现在处于推理(翻译)阶段。
1.输入
(1)源语言序列 (Source Sequence)
- 英文句子: “Hello, how are you?”
- 经过分词处理后: [“Hello”, “,”, “how”, “are”, “you”, “?”]
(2)目标语言序列 (Target Sequence)
- 中文句子: “你好,你好吗?”
- 经过分词处理后: [“你好”, “,”, “你”, “好”, “吗”, “?”]
(3)输入嵌入
- 词嵌入 (Word Embedding) : 将每个单词或标记映射为固定维度的向量。
- 例如,
"Hello"映射为向量 。
- 例如,
- 位置编码 (Positional Encoding) : 为每个 Token 注入位置信息
- 例如, 位置编码向量为 。
- 最终输入嵌入 : 词嵌入与位置编码相加, 形成最终的输入嵌入。
2.编码器
(1)多头自注意力机制 (Multi-Head Self-Attention)
- 编码器中的每个 Token 会计算与其他所有 Token 的相关性(注意力分数)。
- 例如,”Hello” 会计算与 “Hello”、”,”、”how”、”are”、”you”、”?” 的相关性。
- 多头机制将输入分割成多个子空间,分别计算注意力,然后将结果拼接起来。
(2)前馈神经网络 (Feed-Forward Neural Network)
- 对每个 Token 的特征进行非线性变换。
(3)残差连接和层归一化
- 每个子层后面都接有残差连接和层归一化。
编码器经过多层(假设为 6 层)处理后,将源语言序列编码为一个固定长度的上下文向量 (Context Vector)。
3.解码器
解码器以自回归的方式逐步生成目标语言序列。以下是详细的迭代生成过程:
1.初始状态
- 解码器的初始输入是一个特殊的起始标记(例如
<sos>,表示 “start of sentence”)。 - 假设起始标记
<sos>的嵌入为[0.5, 0.5, 0.5, ...]。
2.生成第一个 Token:
(1)掩码多头自注意力机制(Masked Multi-Head Self-Attention)
- 由于解码器只能看到之前的位置,因此对
<sos>进行掩码处理。 - 计算
<sos>的自注意力,得到更新后的状态。
(2)编码器 – 解码器注意力机制(Encoder-Decoder Attention)
- 使用编码器的输出(上下文向量)作为键(Key)和值(Value),解码器的当前状态作为查询(Query)。
- 计算注意力分数,得到与源语言序列相关的特征。
(3)前馈神经网络
- 对特征进行非线性变换。
(4)线性层和 Softmax
- 经过线性层,将特征映射到目标语言的词汇表大小的维度。
- 使用 Softmax 函数计算每个 Token 的概率分布,选择概率最高的 Token 作为输出。
- 假设生成的 Token 是 “你好”。
3.生成第二个 Token:
(1)更新输入
- 将之前生成的 Token”你好” 加入到解码器的输入序列中,即
[<sos>, "你好"]。
(2)掩码多头自注意力机制
- 对
[<sos>, "你好"]进行掩码处理,确保只能看到之前的位置。 - 计算
<sos>和 “你好” 的自注意力,得到更新后的状态。
(3)编码器 – 解码器注意力机制
- 使用编码器的输出作为键和值,解码器的当前状态作为查询。
- 计算注意力分数,得到与源语言序列相关的特征。
(4)前馈神经网络
- 对特征进行非线性变换。
(5)线性层和 Softmax
- 经过线性层,将特征映射到目标语言的词汇表大小的维度。
- 使用 Softmax 函数计算每个 Token 的概率分布,选择概率最高的 Token 作为输出。
- 假设生成的 Token 是 “,”。
4.后续步骤
- 重复上述过程,逐步生成 “你”、”好”、”吗”、”?” 等 Token。
- 当解码器生成结束标记(例如
<eos>,表示 “end of sentence”)时,翻译完成。
4.输出
- 生成的目标语言序列:
["你好", ",", "你", "好", "吗", "?"],即 “你好,你好吗?”。
Transformer 在机器翻译中的迭代生成过程如下:
- 编码器将源语言序列编码为上下文向量。
- 解码器以自回归的方式逐步生成目标语言序列。
- 每次生成一个 Token 后,将其加入到解码器的输入中,继续生成下一个 Token。
- 重复上述过程,直到生成结束标记。
这种自回归的生成方式使得 Transformer 能够生成流畅且准确的翻译结果。
四、组件详细解读
1.多头自注意力机制
2.前馈神经网络
3.掩码多头自注意力机制
4.编码器-解码器注意力机制
(1)输入
(2)Query(查询),Key(键),Value(值)的计算
(3)计算注意力分数
(4)计算注意力权重
(5)计算加权和